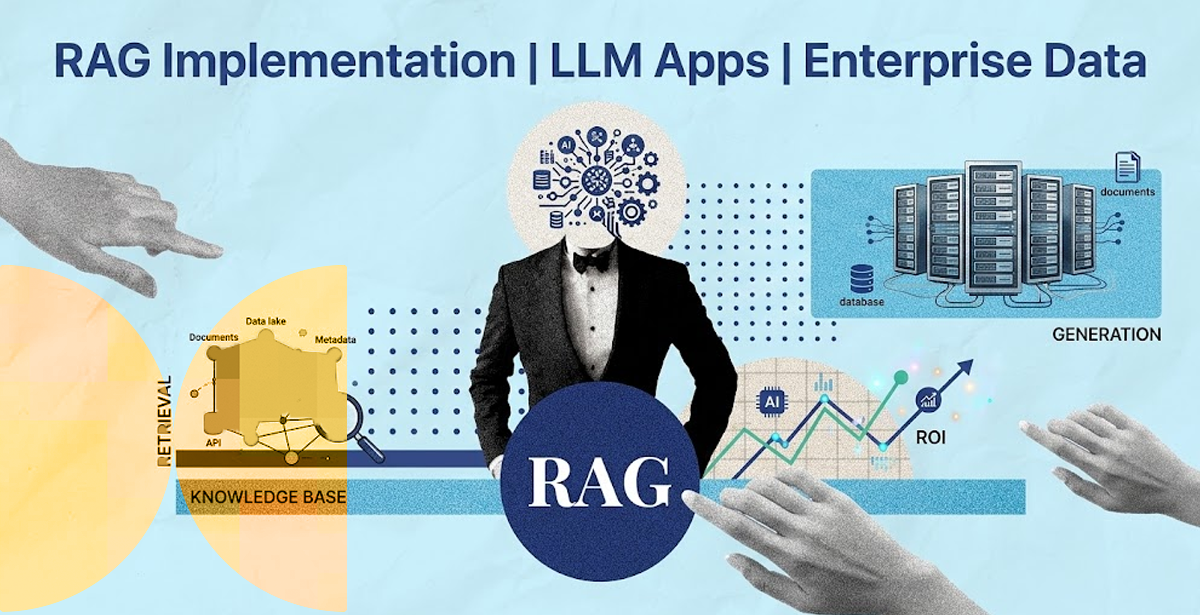
RAG Implementation Services for Building Knowledge-Grounded LLM Applications
Generic large language models are impressive. But they’re also dangerous in enterprise settings.
Ask a base LLM about your internal compliance policies, your product specifications, or last quarter’s customer contracts. It’ll confidently answer based on whatever it was trained on rather than your data, context, and reality.
That gap is exactly what RAG implementation services are built to close.
Retrieval-Augmented Generation (RAG) grounds every model response in your actual organizational knowledge. It makes AI outputs accurate, auditable, and genuinely useful at scale.
The following guide will help you further understand how RAG works, what enterprise RAG implementation actually requires, and why the partner you choose matters.
What Is RAG and Why Does Enterprise AI Need It?
RAG is an AI architecture that combines the generation capability of a large language model with a retrieval system that fetches relevant context from your own data before responding.
Instead of drawing on static training data, a RAG system queries a live knowledge base: your documents, databases, CRM records, product catalogs, or regulatory libraries. It injects that context directly into the model prompt before the LLM generates a response.
RAG is also different from fine-tuning. Fine-tuning changes what a model knows. RAG changes what a model can access at inference time. For enterprise use cases with frequently changing data, RAG is typically faster to implement, cheaper to maintain, and easier to update.
The original RAG research from Meta AI, published in 2020, established this as the foundational pattern for grounding language models in external knowledge. It demonstrated measurable accuracy gains on knowledge-intensive tasks compared to base LLMs operating without retrieval.
For enterprises, this isn’t a performance experiment. It’s the architecture that makes AI deployments trustworthy in regulated, high-stakes environments.
💡 Traditional RAG improves AI responses by grounding them in enterprise knowledge, but it often struggles with complex relationships across systems, people, and data. That’s where GraphRAG implementation comes in handy. Graph Retrieval-Augmented Generation (GraphRAG) uses knowledge graphs to understand context, dependencies, and connections. That way, it ensures more accurate, explainable, and context-aware AI outcomes for enterprise-scale decision-making.
The Core Components of Enterprise RAG Implementation
Enterprise rag implementation involves several interconnected layers. Each must be engineered for scale, security, and accuracy.
- Data ingestion and Chunking – Documents, PDFs, databases, and APIs are preprocessed and split into semantically meaningful segments. The quality of this step directly affects what the retrieval layer can find.
- Embedding and Vector Indexing – Each chunk is converted into a vector representation using an embedding model and stored in a vector database. DPL’s RAG stack includes Pinecone, ChromaDB, and GraphRAG, selected based on retrieval patterns, scale, and latency requirements for each deployment.
- Retrieval – When a user submits a query, the system embeds it and retrieves the most semantically similar chunks. Those chunks are passed as context to the LLM.
- Generation – The model synthesizes a response grounded in the retrieved context, not in its pre-training weights.
Frameworks like LangChain provide orchestration scaffolding for these components. But the design choices within each layer — what to chunk, how to embed, what to retrieve — are what determine real-world performance.
Misconfigure the chunking strategy or retrieval parameters, and the whole system degrades, regardless of how capable the underlying model is.
Why Custom RAG Development Is Non-Negotiable for Enterprise
Off-the-shelf RAG templates exist. They work well in demos. However, they fail in production enterprise environments because enterprise data isn’t uniform.
Your data may span structured databases, unstructured PDFs, semi-structured APIs, and real-time event streams — often in the same workflow. Domain-specific terminology must be handled correctly by the retrieval logic. Access controls must further map to your existing security model. Moreover, outputs must be explainable and auditable.
Custom RAG development addresses these constraints from the ground up. A generic pipeline can’t account for how a healthcare provider structures clinical notes, how a law firm organizes case precedent, or how a financial institution’s compliance documentation is versioned and updated.
Enterprise RAG solutions that last are built for the data environment they operate in, not against it.
What to Expect From a RAG Solution Provider
Good RAG development services go well beyond deploying a vector database and wiring it to an LLM API. The work is architectural and iterative.
A capable RAG solution provider will –
- Assess your existing data infrastructure before touching any model
- Evaluate retrieval quality with real user queries, not synthetic benchmarks
- Design for failure modes: retrieval gaps, latency spikes under load, and edge cases where the model generates plausible but unsupported responses
They’ll also plan for sustainability, considering questions such as:
- How is the knowledge base kept current?
- How are new document types onboarded?
- How does the system evolve as your LLM vendor releases new versions?
So, remember to touch on these points when consulting with RAG implementation services.
💡 RAG doesn’t operate in isolation — it relies on clean, governed, and well-structured data pipelines to deliver accurate results. Providers focused only on deploying AI models often overlook the foundational work required for scalable retrieval. Experienced partners understand that successful RAG and GraphRAG implementations depend on strong data architecture, integration, metadata management, and continuous data quality practices. That’s why you should assess their data engineering services before making a decision.
How DPL Builds Enterprise RAG Solutions
At DPL, RAG implementation begins with a structured discovery phase. We map your data sources, define retrieval scope, and validate the approach through a focused proof of concept before committing to full build-out.
Our engineering team works with Pinecone and ChromaDB for vector storage, and GraphRAG for knowledge-graph-augmented retrieval on complex, interconnected enterprise datasets. We build with leading LLMs including OpenAI, Llama, Mistral, and DeepSeek, selecting the right combination based on your accuracy, cost, and latency requirements.
- For Sindh Ombudsman, we built an AI-powered NLP platform on Amazon Bedrock that classifies 1,000+ citizen complaints daily with 92% accuracy.
- For Pause. Breathe. Reflect., we built the Michael AI Bot — a generative AI companion that analyzes user emotions in real time and recommends personalized sessions from a library of 2,000+ mindfulness practices.
- For National Janitorial Solutions, our document AI pipelines process 50,000+ work orders daily with zero manual intervention.
In these industries, a hallucinated response isn’t just bad user experience; it’s a liability.
Every system we deliver is designed for your team to own and extend. We build independence, not dependency.
Get RAG Development Services for AI That Actually Knows Your Business
Generic LLMs will always have a knowledge ceiling. RAG removes it.
With the right rag implementation services, your enterprise can deploy AI that answers from your contracts, your protocols, your products, and your data. Responses that are grounded, traceable, and built for how your organization actually works.
You can entrust our team with this task. We have the technical depth and production track record to get it right. Talk to us about your data environment and let’s scope what a custom RAG implementation would look like for your organization.

Related Articles
-
Enterprise Generative AI – Deploying LLMs With the Guardrails Large Organizations Require
05-Jun-2026 Salman Naseer
-

Choosing the Right AI App Development Company to Build Intelligent Apps
18-May-2026 Talha Saleem
-

AI Proof of Concept Development: The Smart Way to Validate Innovation
14-May-2026 Maha Yaser