AI DevOps Services – Bringing CI/CD Discipline to Machine Learning Deployments
Approximately, 87% of machine learning (ML) projects never reach production. Models get built, validated in notebooks, and then stall. The gap between a data scientist’s laptop and a live system is where most ML initiatives die.
The problem is not the model. It is the process.
Traditional software teams solved this with CI/CD pipelines. Automated build, test, and deploy cycles removed manual handoffs from the release path. ML needs the same discipline.
That is where AI DevOps services change the equation.
Applying CI/CD principles to the full ML lifecycle means models reach production reliably. Teams keep them accurate as data evolves. Updates ship on a cadence that matches business requirements, not quarterly release windows.
Why ML Deployments Break Without CI/CD Structure
A trained model is not static software. It degrades as real-world data diverges from its training distribution. That is data drift. Environment mismatches add a second failure vector.
A model validated locally may behave differently inside a containerized inference endpoint at scale. Then there is the handoff problem. When model promotion depends on Slack messages, deployment becomes a black box.
Traditional CI/CD tools version code. They do not version datasets, feature pipelines, or model weights. Teams bolt on manual steps for training runs and validation. That creates exactly the friction CI/CD was designed to eliminate.
The cost too is immediately apparent. For instance, before DPL’s engagement, National Janitorial Solutions ran deployments that took four hours. Manual effort was constant.
After fully automated CI/CD pipelines on Amazon ECS, deployment time dropped to under one minute. Manual deployment effort fell by 90%.
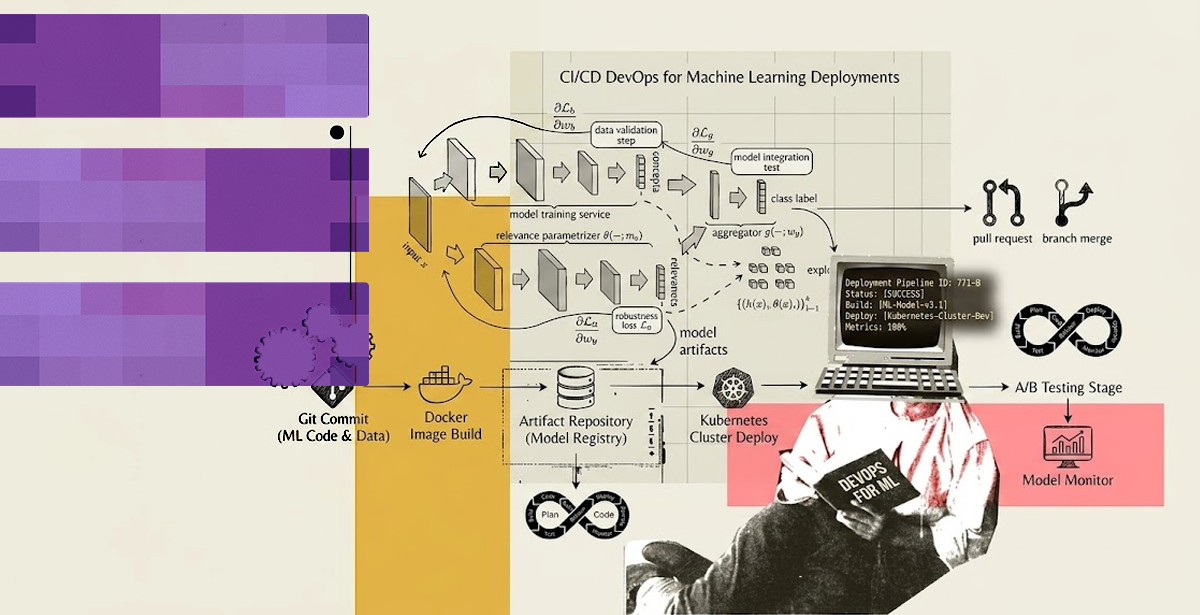
What CI/CD for Machine Learning Actually Looks Like
Google Cloud’s MLOps automation framework defines three maturity levels:
- Level 0 is fully manual: ad hoc training runs, no pipeline.
- Level 1 introduces automated training pipelines.
- Level 2 is full CI/CD automation.
At Level 2, new data triggers a pipeline. It trains, validates, and deploys a new model version automatically. Human intervention only kicks in when a quality gate fails. Getting there means rethinking the pipeline from the data layer up.
Automated Model Validation Gates
Before any model version reaches staging, it must pass a validation suite. This includes accuracy thresholds, latency benchmarks, data schema checks, and bias evaluations where required. These gates run automatically. A failing gate blocks the deployment, exactly as a failing unit test blocks a code release.
When DPL built the AI-powered complaint platform for Sindh Ombudsman, automated validation was embedded in every deployment cycle. The model achieved 92% classification accuracy in production. Deployment frequency increased by 42%. Government-grade compliance was maintained throughout.
Environment Parity and Containerized Inference
Container orchestration for production inference workloads ensures the model that passed validation is the model that runs in production. The model artifact, its dependencies, and its runtime environment must be versioned together. Not an approximation of it.
💡For production inference in AI DevOps, consistency is non-negotiable—only the exact model that passed validation should run in production. This requires tightly coupling the model artifact, its dependencies, and its runtime environment through strict versioning and immutable deployments. Anything less introduces drift between testing and real-world behavior, turning “validated performance” into an unreliable approximation. So, make sure to thoroughly discuss this aspect while hiring the best cloud provider for container orchestration.
Where Intelligent DevOps Changes the Equation
Standard CI/CD discipline gets ML models to production. Intelligent DevOps, or AI-driven DevOps applied to ML workloads, keeps them there.
AIOps platforms apply machine learning to the DevOps toolchain. They monitor pipeline health, detect anomalies in model outputs, and predict infrastructure failures. For ML workloads, this matters most at the inference layer.
A degraded model may not cause a system error. It just quietly returns worse predictions. Without intelligent monitoring, that degradation compounds until it shows up in business metrics.
AI and ML are actively transforming CI/CD pipelines into intelligent, autonomous workflows, and ML inference is where that intelligence matters most.
The practical application of ml-enhanced DevOps tooling covers three patterns.
- Automated canary deployments route a small traffic percentage to a new model version, with automatic rollback if KPIs slip.
- Drift detection triggers retraining when incoming data diverges beyond a threshold.
- Predictive scaling anticipates inference load spikes before they cause latency issues.
Shipping is a moment. Operating is continuous.
Applying AI DevOps in Practice
Building CI/CD discipline for ML requires alignment between data science, MLOps, and platform engineering teams. The tooling follows from that alignment.
The starting point is a version-controlled feature store that treats data pipelines as first-class code. Next comes a model registry tracking trained versions with their metadata: training data hash, hyperparameters, and validation results.
Finally, a deployment pipeline promotes models through dev, staging, and production with automated gates at each step.
A model monitoring layer closes the loop. Post-deployment telemetry triggers retraining when drift is detected. Container orchestration handles packaging and rollout mechanics. A CI/CD platform manages triggers and gate logic.
This pattern holds even in extreme environments. For Pakistan Air Force, DPL deployed a fully air-gapped Kubernetes cluster with zero external connectivity. On-premises GitLab CI/CD ran multiple deployments daily. Pipeline execution time came in under 10 minutes. The team had previously shipped monthly.
If CI/CD discipline works in a classified defense data center with no cloud access, it works anywhere. DPL’s MLOps services are built to implement this infrastructure for teams moving fast, without assembling each layer from scratch.
CI/CD Discipline Is What ML Deployments Have Been Missing
ML models do not fail because data scientists build bad models. They fail because the operational infrastructure was never designed to sustain them.
CI/CD discipline, applied to the full ML lifecycle through purpose-built AI DevOps services, closes that gap.
Automated validation, containerized deployment, intelligent monitoring, and drift-triggered retraining transform a one-time model launch into a continuously operating system.
If your team ships models manually or runs production AI without drift monitoring, the cost compounds daily. DPL’s ML engineering expertise is available to design the right pipeline architecture from the ground up.