What Is Retrieval Augmented Generation and Why Your Enterprise AI Needs It
Every enterprise AI conversation eventually hits the same wall: a large language model that sounds confident but has no idea what is actually happening inside your business. One that can’t see yesterday’s support tickets, your procurement contracts, or the regulatory memo your legal team circulated this morning.
And that’s where RAG can help.
Retrieval augmented generation (RAG) gives an LLM a live connection to your authoritative data, and it does so without the cost, risk, and rigidity of fine-tuning. That’s why, RAG should be the first serious AI investment for most enterprises, not the last.
If this piques your interest, and it honestly should, here’s our take on this topic based on real DPL AI engineering engagements across healthcare, finance, government, and facilities management.
Retrieval Augmented Generation Explained
Retrieval augmented generation is an AI pattern that pairs a large language model with an external knowledge retrieval system. The concept was formalized in Meta AI’s 2020 paper on retrieval-augmented generation, and it has since become the dominant pattern for enterprise LLM deployments.
Instead of relying solely on what the model learned during training, the system fetches relevant passages from a trusted data source at query time and feeds them into the prompt. The LLM then generates its answer grounded in that fresh, authoritative context.
Basically, RAG turns a general-purpose LLM into a well-briefed expert. Every time a user asks a question, the system hands the model the exact documents it needs to answer.
If the data changes, the answer changes. That way, there’s no retraining, no waiting weeks for a new model checkpoint, and no risk that the model repeats stale information with misplaced confidence.
RAG Architecture: The Four Essential Components

A production-grade RAG architecture has four moving parts, and each one shapes how the final answer performs.
First, the ingestion pipeline. Your documents (PDFs, wikis, knowledge bases, databases) are chunked, cleaned, and converted into vector embeddings. Quality here determines everything downstream.
Second, the vector store. Embeddings live in a specialized database such as Pinecone, ChromaDB, or a graph-aware store for GraphRAG setups.
Third, the retriever. When a user submits a query, the retriever searches the vector store and often re-ranks results using hybrid search or domain-specific signals.
Fourth, the generator. A RAG LLM such as Mistral, Gemini, or an OpenAI model synthesizes the retrieved context into a coherent answer, often with inline citations.
Add observability, evaluation, and guardrails on top, and you have a system that enterprises can actually deploy.
💡Always plan for data engineering when planning for RAG. Data engineering underpins RAG by building pipelines that collect, clean, transform, and index data for efficient retrieval. It ensures high-quality, up-to-date information is stored in vector databases, enabling accurate responses. Without strong data engineering, RAG systems struggle with irrelevant results, latency issues, and unreliable outputs. These, in turn, reduce overall effectiveness and trust. So, make sure to connect with a reliable data engineering company.
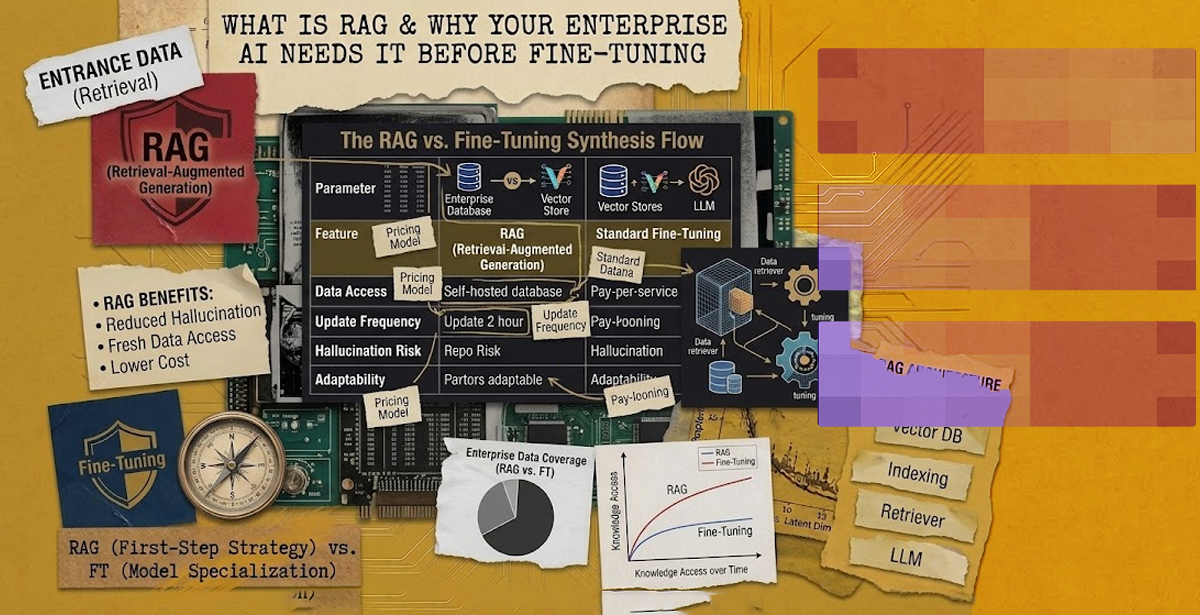
Why RAG Should Be on Your RAG LLM Roadmap Before Fine-Tuning
Fine-tuning has a glamour problem. It sounds like the serious, technical option, so executives often assume it’s the right first step. Yet that’s not the case for most enterprise use cases.
Fine-tuning rewrites a model’s weights to adjust behavior, style, or domain reasoning. It’s expensive, slow, and frozen at the point of training. A fine-tuned model that learned your 2025 product catalogue will happily recommend discontinued SKUs in 2026 unless you retrain it.
RAG, by contrast, adapts instantly. Update the source document, reindex, and the next answer reflects the change. It costs less, protects your intellectual property by keeping proprietary data outside the model weights, and makes governance simpler because every answer can trace back to its source.
A pragmatic sequence looks like this:
- Start with RAG to unlock immediate value from your existing documents
- Observe where the model still struggles
- Only consider fine-tuning for the narrow behaviors that retrieval alone cannot fix
Teams that validate the concept through rapid proof of concept development make far smarter fine-tuning decisions later.
RAG vs. Fine-Tuning vs. Prompt Engineering: Which to Opt for and When?
Prompt engineering is the primary mechanism for steering model behavior via the system prompt. It functions as the runtime instruction set, defining the persona, constraints, and output schema (e.g. JSON) for the model.
It further delivers minimal latency, zero compute overhead for training, and immediate iteration.
That said, it’s governed by the Context Window limit. As the complexity of instructions grows, the model may stumble when attention mechanisms fail to weigh peripheral instructions effectively.
On the other hand, retrieval augmented generation decouples the model’s reasoning engine from its knowledge base. By utilizing a vector database and embedding models, RAG injects relevant document chunks into the prompt at inference time.
Therefore, it’s best for use cases requiring data freshnes (e.g., stock prices, news) or auditability. RAG provides a traceability chain, allowing the system to cite specific source chunks. This, in turn, significantly mitigates stochastic hallucinations.
So, if you’re interested in the integration of petabytes of proprietary data without the astronomical costs of retraining, RAG it is.
As for fine-tuning (specifically via PEFT or LoRA), the process involves updating the actual weights of the model. So, this isn’t a mechanism for teaching the model new facts, but rather for teaching it a new domain-specific logic or syntax.
Based on this, you can use it when the desired output follows a highly rigid structure or a specialized linguistic pattern that can’t be consistently elicited via few-shot prompting.
Do keep in mind that fine-tuning is a static update though. If the underlying data changes, the model remains tethered to its training state. It’s a high-cost, high-complexity intervention reserved for optimizing performance on narrow, stable tasks.
Where RAG AI Delivers Enterprise Wins
Certain workflows are tailor-made for RAG AI. For instance –
- Customer support automation is the obvious one; agents and chatbots answer product questions using current documentation rather than a six-month-old training snapshot.
- Compliance and legal research teams can also query thousands of contracts or regulatory texts and receive cited, source-linked answers.
- Operations and knowledge management give frontline staff instant access to procedures, manuals, and historical ticket data.
- In financial and clinical settings, analysts and clinicians consult structured and unstructured data with full provenance.
DPL’s production systems show the pattern in action. The Jan-IT platform we built for National Janitorial Solutions processes more than 50,000 work orders per day using Google Document AI and a GPT-based extraction layer, saving hundreds of hours weekly.
Similarly, the Sindh Ombudsman’s AWS Bedrock-powered CRM cut complaint processing time by 65% while achieving 92% AI categorization accuracy, an outcome that would have been impossible without retrieval-grounded models.
What to Get Right Before You Build
Before writing a line of RAG code, pressure-test three questions.
- Is your data retrieval-ready? Fragmented, inconsistent, or low-quality sources will hobble any RAG system.
- Do you have a clear success metric? Answer accuracy, citation rate, deflection rate, and time-to-answer each tell different stories.
- Have you defined guardrails? Hallucination controls, access restrictions, and human-in-the-loop review must be designed in from day one, not bolted on after launch.
A PoC cycle is the cheapest insurance policy. A four-to-eight-week engagement validates technical feasibility, surfaces data issues early, and produces the evidence business stakeholders need to commit to a full RAG rollout.
Interested in Hiring RAG Implementation Services?
Retrieval augmented generation is not a trend to track; it’s the architectural default for enterprise AI in 2026.
It’s faster to deploy than fine-tuning, cheaper to maintain, easier to govern, and far more adaptable to the way enterprise knowledge actually changes. Start with RAG, prove the value, and let the data tell you whether fine-tuning ever becomes necessary.
If you are weighing your options, DPL offers end-to-end RAG implementation spanning strategy, data engineering, model selection, deployment, and ongoing MLOps.
Book a discovery call to map your first RAG use case and move from concept to measurable production impact.